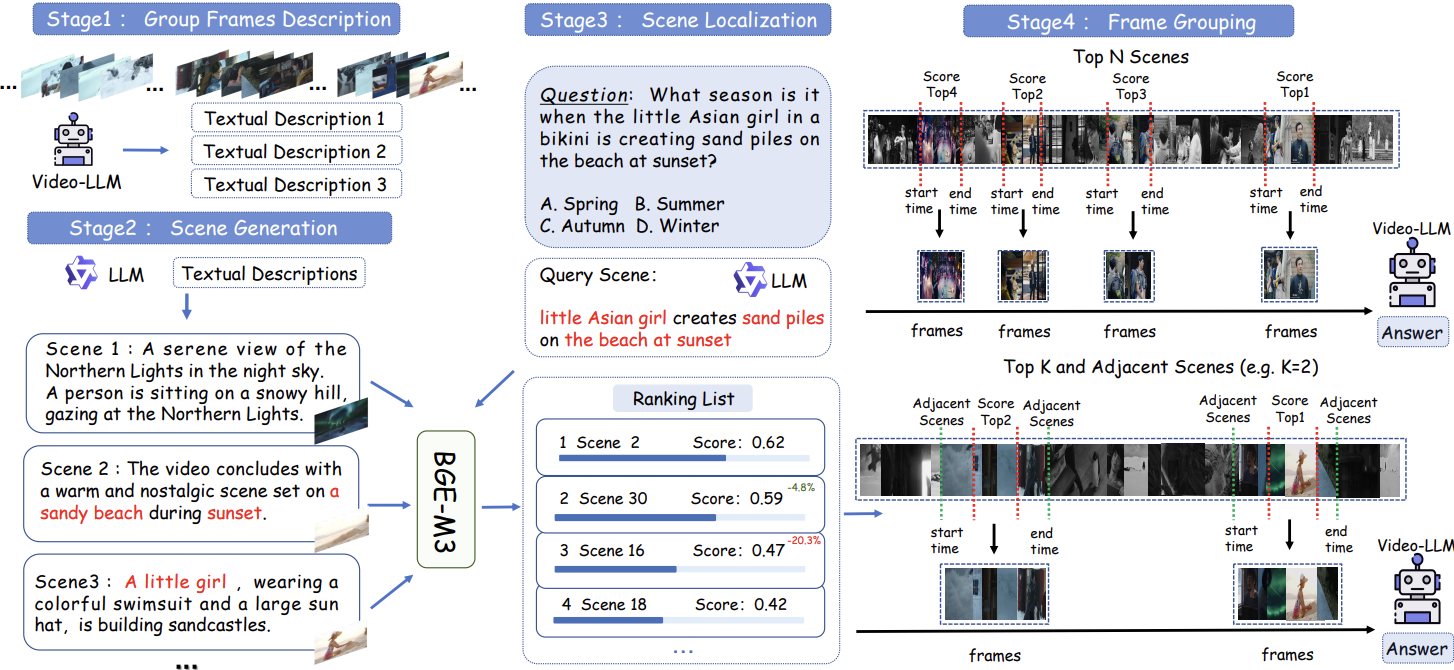
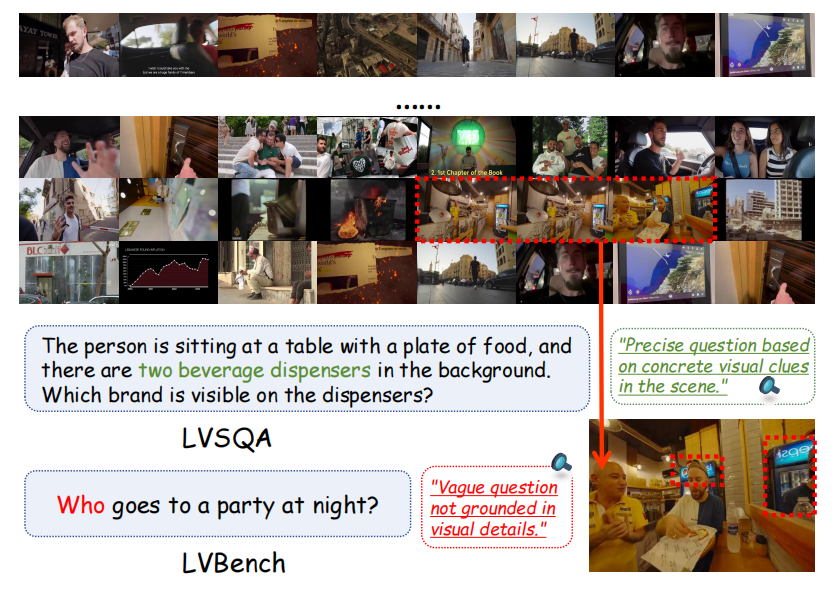
1Guangdong Laboratory of Artificial Intelligence and Digital Economy (SZ), Shenzhen, China2School of Electronic and Computer Engineering, Peking University, Shenzhen, China3School of Computer Science, Wuhan University, Wuhan, China4University of Science and Technology of China, Hefei, China